Given a divergence measure $d(P, Q)$ and two distribution $P$ $Q$, what is the effect to the divergence $d(P^m, Q^m)$ as $m$ increases ? Intuitively, the divergence shall increase since product distribution emphasize the difference of the distribution. In this work by Zinan et.al , the upper and lower bound of $d(P^m, Q^m)$ is given for the divergence measure :
\begin{eqnarray}
&& d _{p}(P,Q) = \mathop{\sup} _{S} [P(S) - Q(S)]
\end{eqnarray}
This measure is closely related to the optimal successful detection probability $P _{\rm opt}$ in the binary hypothesis testing :
\begin{eqnarray}
&& P _{\rm opt} = \mathop{\sup} _{S} [\pi _1 P(S) + \pi _2 (1 - Q(S))] = \pi _2 + d _{p}(\pi _1 P, \pi _2 Q) = \frac{1}{2} + d _{\rm TV}(\pi _1 P, \pi _2 Q)
\end{eqnarray}
where $\pi _1, \pi _2$ are the prior distribution of the hypothesis, and $d _{\rm TV}(P, Q)$ is the total variance distance :
\begin{eqnarray}
&& d _{TV}(P,Q) = \frac{1}{2} \sum _{\omega \in \Omega} |P(\omega) - Q(\omega)|
\end{eqnarray}
What makes the work by Zinan et.al interesting is that if certain local property is satisfied for the distribution pair $(P, Q _1)$ but not for $(P, Q _2)$, and assume $d _p(P, Q _1) = d _p(P, Q _2)$, then the possible value region of $d _p(P^m, Q^m _1)$ splits away from that of $d _p(P^m, Q^m _2)$. This local property is called $(\epsilon, \delta)$ -mode collapse, defined as:
\begin{eqnarray}
&& P,Q \; {\rm has \; (\epsilon, \delta)- mode \; collapse \; :}\exists S \; {\rm s.t.} \; P(S) \geq \delta \; , Q(S) \leq \epsilon
\end{eqnarray}
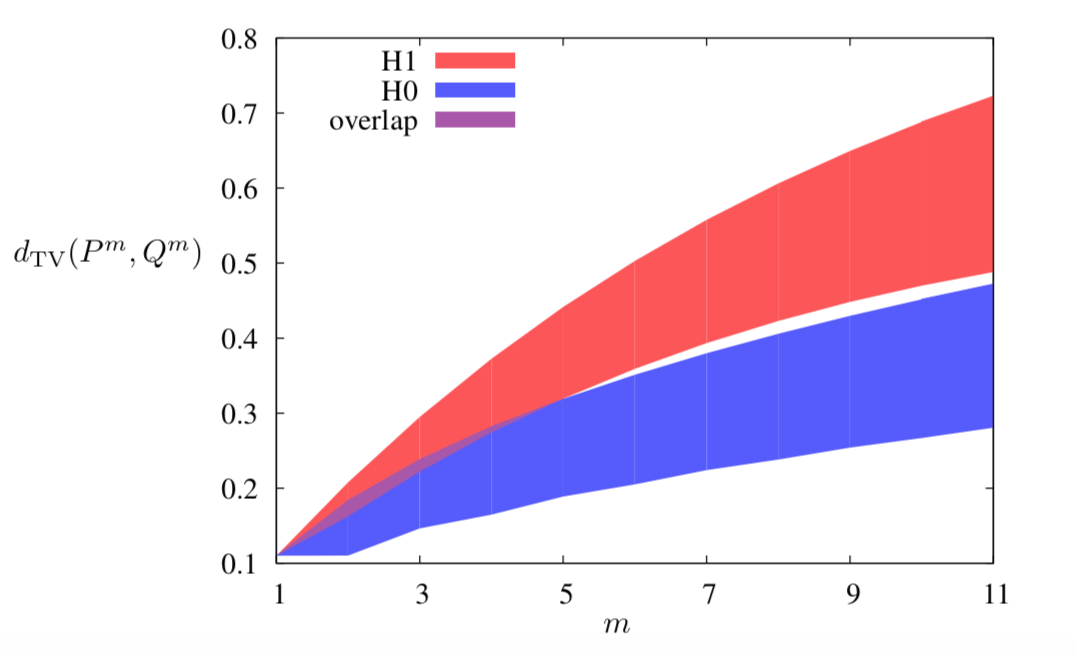
Interestingly, similar result was given in the quantum literature by Jonas
Maziero for trace distance:
\begin{eqnarray}
&& d _1 (\rho _1, \rho _2) = \frac{1}{2} \Vert \rho _1 - \rho _2 \Vert _1 = {\rm Tr} (\sqrt{(\rho _1 - \rho _2)^{\ast} ( \rho _1 - \rho _2)})
\end{eqnarray}
So, I think it would be fun to dig into the quantum counterpart of Zinan’s work.
